Optimizing Chat Systems with Hazelcast: Efficient Message Routing for Grindr


One of the biggest projects we’ve undertaken, probably since Grindr was founded, is a complete rebuild of our chat system. For an application like Grindr, a robust chat system is essential as it is core to how our users interact with each other. Every day, millions of chats are sent through Grindr, facilitating connections, conversations, and community-building among our users. Ensuring that these interactions happen seamlessly and reliably is our top priority, which is why we’ve invested significant resources into this overhaul, and I am excited to share more about the updates we have made.
Like most chat systems, messages are sent and received using websockets. When the app starts up, a websocket session is opened, authenticated, and kept alive while the app is open. Each time a message is sent, the recipient receives their copy of the message over their websocket connection.
Also like most modern services, our chat platform is deployed into a container based environment. This means we’re running multiple pods for each service. Imagine we have some service that is handling the websockets I just mentioned — call this the “websocket-service.” When the app starts up, and a websocket connection is established, one of the running websocket-service pods is selected to handle that connection.
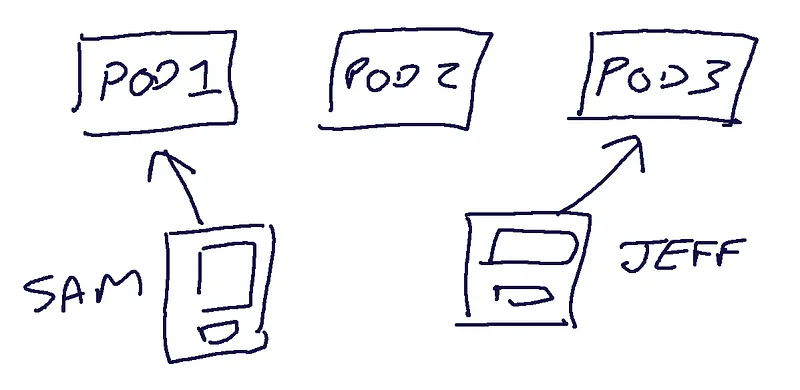
You can see here that there are three websocket-service pods running. Sam’s phone has an open websocket to pod 1, and Jeff’s phone has an open connection to pod 3. Persisting a sent message is trivial — the pod with the connection can perform any message checks, sanitization and logic required — and then send a response back to the sender
Message Routing
However, one of the challenges becomes how to route messages from the pod that is handling the sent message to the pod that has a connection open for the recipient.
When user Sam sends a message to user Jeff, the sender’s websocket frame is delivered to the pod that user Sam is connected to (pod1). However the recipient’s websocket frame must originate from pod3, since that’s the pod that Jeff’s phone is connected to. Further complicating matters are the fact that users may have multiple devices operating at the same time (i.e Jeff could have connections to pod3 and pod2 and both need to receive the message), and the fact that these pods are ephemeral and should support rolling deployments.
A simplistic approach involves putting all outgoing messages onto a single pub/sub channel (e.g. a Kafka topic) and having all pods subscribe to all events, skipping messages for consumers not connected to their pod. But that approach won’t scale horizontally, limiting your message throughput to the maximum number of messages each single pod can handle. Other alternatives we considered include Akka and a Redis pub/sub channel per pod.
Hazelcast
The solution employed at Grindr is to create a Hazelcast distributed topic per pod as part of the pod’s initialization logic. Each pod consumes only from the single topic created for it, but any pod can publish a message to any topic.
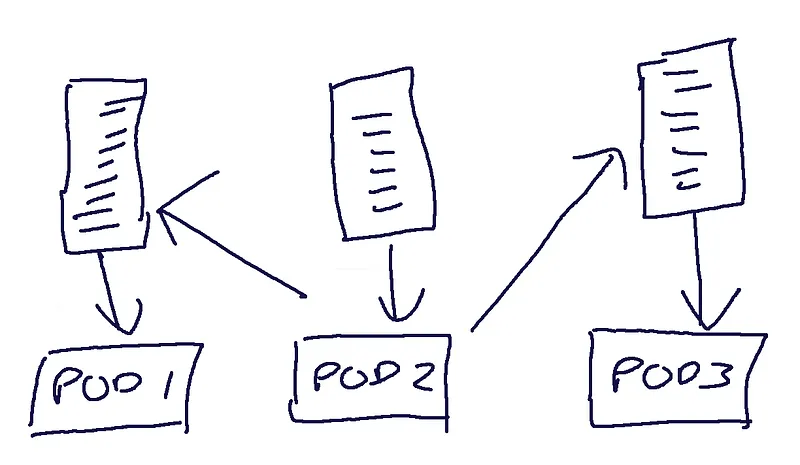
As you can see in the above diagram, we have three topics and three pods. Each pod subscribes to the topic they own, and in this example, pod2 is broadcasting messages to each of the other two topics. The idea is that when a pod receives an incoming message from a websocket, it publishes to each of the topics that have an open connection for the recipient.
The next part of the design is determining a way for the pod handling a message to know which topics to broadcast to. In order to ensure that the system scales as we add more users and more messages we need to only publish to the topics that are handling that recipient. As mentioned earlier, we can’t simply broadcast to every pod’s topic otherwise we’d be back to the simplistic approach that would be limited by the throughput of any single pod.
We solve this by using a Hazelcast distributed map, which is a shared data structure which any client can add a mapping to.
When a user connects to a pod, this map is updated with a mapping between the user’s id (unique per user) and the pod-id (generated on pod startup). So now, when a message is received from Sam that is intended to be sent to user Jeff, we look in the map for any pod-id’s associated with Jeff. With this list of Jeff’s pod-ids, we can publish outbound messages to only the topic for each of those pods.
When a user disconnects (shuts the app down, or the network goes away), the mapping is removed. So this map is a semi-real time association of which users are online.
Wrap up
What makes Hazelcast very useful here is that it provides both parts of the solution in a single service. We could store the distributed map using a redis cluster for instance, by having the user-id be the key, and the value be a Redis set of pod-ids. And instead of a distributed topic per pod, we could have a RabbitMQ queue or an S3 queue per pod. But hazelcast brings it all together in a single solution, with a very easy to use Java API.
This new system is designed to support the massive volume of messages exchanged daily, providing a faster, more reliable, and secure experience for our users.









.jpg)



.webp)




